LLaVA works by teaching an LLM (Llama2) to “understand” embeddings from an image model (CLIP). What happens if you replace the embeddings with randomness and ask the LLM questions about what it sees?
Hacking LLaVA
After loading the LLaVA model, we can inject a function that runs after clip embed but before projection to the LLMs token latent space.
# load LLaVA using HF transformers
tokenizer, model, image_processor, context_len = load_pretrained_model(
"liuhaotian/llava-v1.5-13b",
model_name="llava-v1.5-13b",
model_base=None,
load_8bit=False,
load_4bit=False)
# inject hook that allows modifying the generated clip embed
tower = model.get_vision_tower()
tower.register_forward_hook(random_forward_hook)
# if global alter_seed set, override embed with randn of same shape
alter_seed = None
def random_forward_hook(module, input, output):
if not alter_seed is None:
print("overriding image embedding with seed: ", alter_seed)
torch.manual_seed(alter_seed)
output[0] = torch.randn_like(output[0])
return outputYou can try it out by running llava-lies on replicate. This model still asks for an image, to simplify the modification of LLaVA’s code. The hook random_forward_hook above replaces the output with normalized seeded noise.
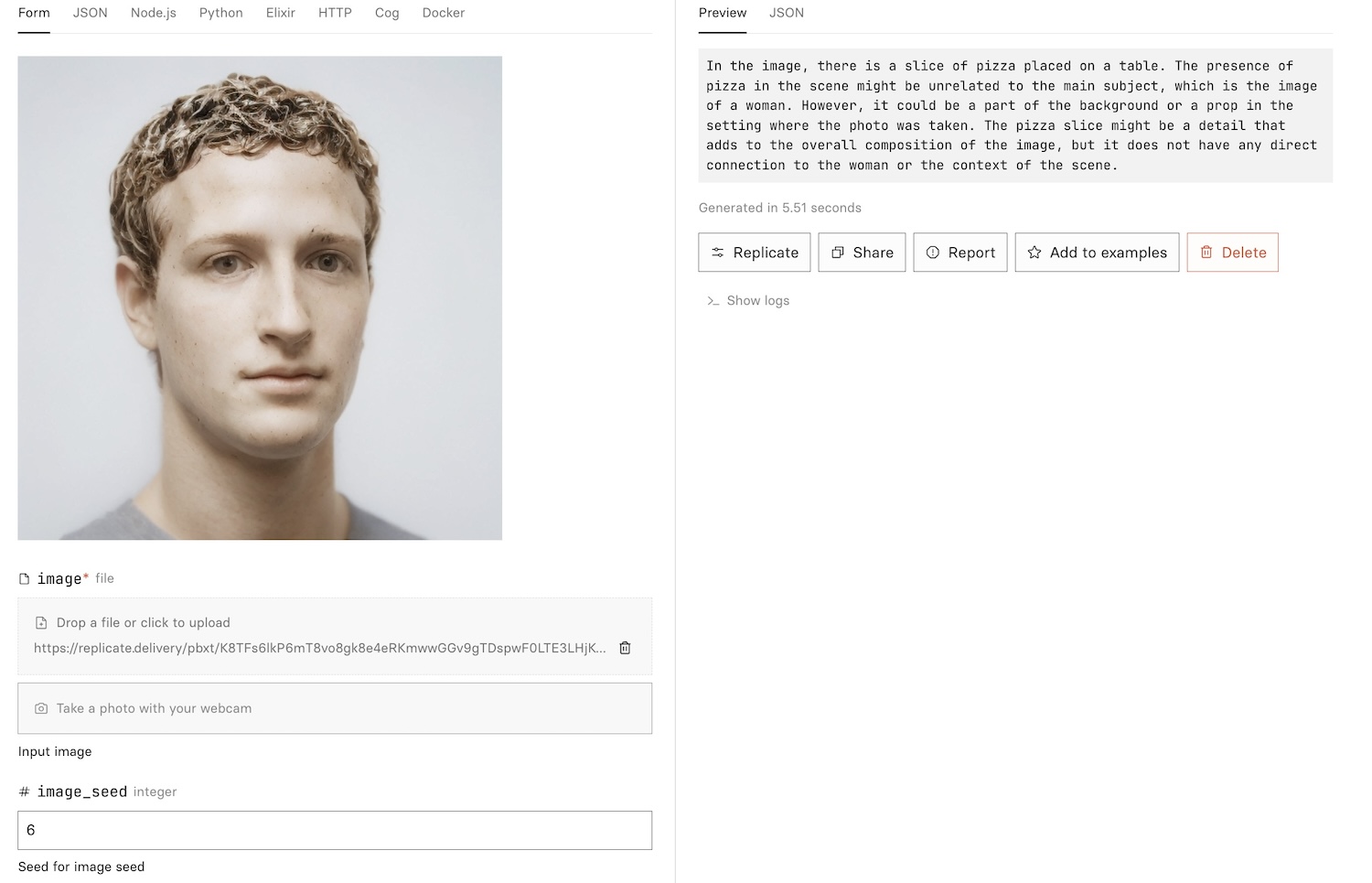
Asking questions
From the paper, we learn that the training prompts were:
- “Describe the image concisely.”
- “Provide a brief description of the given image.”
- “Offer a succinct explanation of the picture presented.”
- “Summarize the visual content of the image.”
- “Give a short and clear explanation of the subsequent image.”
- “Share a concise interpretation of the image provided.”
- “Present a compact description of the photo’s key features.”
- “Relay a brief, clear account of the picture shown.”
- “Render a clear and concise summary of the photo.”
- “Write a terse but informative summary of the picture.”
- “Create a compact narrative representing the image presented.”
Let’s ask the first 10 seeds those questions!
What does it mean?
As the paper’s authors note:
Biases. Bias can be transferred from the base models to LLaVA, both from the vision encoder (CLIP) and the language decoder (LLaMA/Vicuna). This may lead to biased outcomes or unfair representations of diverse content.