Sometimes a single word isn’t enough. What if you could blend tokens or use non-tokens (aka nokens1)?
Let’s explore these ideas, learn more about transformers: the architecture and Hugging Face library.
Installing & Setup
I’m going to use Microsoft’s Phi-2 as it is smaller than Mistral / Llama2. The ideas should transfer to other transformer models.
After pip install transformers torch, we can load our language model to experiment with using the Hugging Face library.
from transformers import AutoTokenizer, PhiForCausalLM
import torch
torch.set_default_device('mps') # set to 'cuda' for Nvidia GPUs
phi = PhiForCausalLM.from_pretrained('microsoft/phi-2')
tokenizer = AutoTokenizer.from_pretrained('microsoft/phi-2')After the download completes, we can test the model by asking it to generate some text.
Generating Text The Old Fashion Way
Before exploring unknown latent spaces, let’s verify we can generate text from a prompt.
With the transformers models you can’t just send in the prompt, we need to manually tokenize (encode) the prompt and then decode the response.
def llm(prompt, max_length=30):
inputs = tokenizer(prompt, return_tensors='pt')
generated_ids = phi.generate(inputs.input_ids,
attention_mask=inputs.attention_mask,
max_length=max_length)
return tokenizer.batch_decode(generated_ids,
clean_up_tokenization_spaces=False,
skip_special_tokens=True)[0]We can verify the snippet works by asking Phi about whippets.
llm("Whippet facts:")Whippet facts:
- The Whippet is a medium-sized dog breed.
- They have a slender and elegant body structure.
In order to use nokens, we need to learn how to generate text from token embeddings.
Token Embeddings
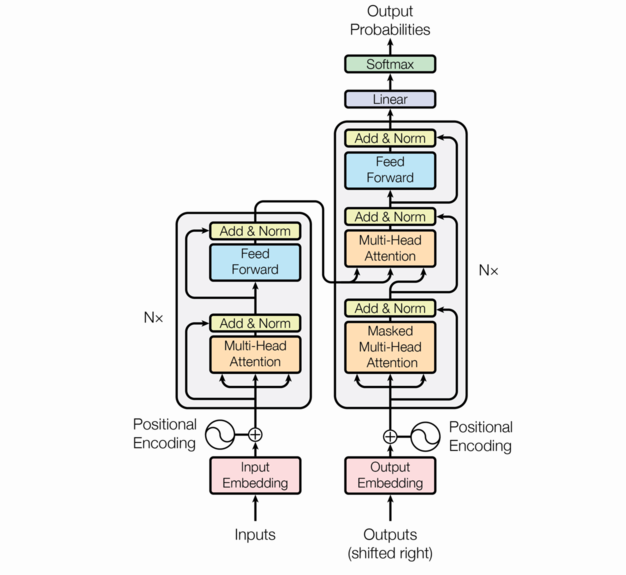
At the bottom of the architecture diagram, we see the first step is embedding the tokens. This is where converting each token into an embedding happens. If you need a refresher on tokens, check out Simon Willison’s interactive GPT Tokenizer Notebook.
Each token becomes a 2560 dimensional embedding. We can see this by running the following code:
prompt = "Hello world :)"
inputs = tokenizer(prompt, return_tensors="pt")
for id in inputs.input_ids[0]:
print(tokenizer.decode(id), id.item(), phi.model.embed_tokens(id))| Token | Id | Token Embedding - 2560 dimensions |
|---|---|---|
"Hello" |
15496 | [-0.0298, -0.0281, 0.0052, …, 0.0336, 0.0179, -0.0231] |
" world " |
995 | [ 0.0178, 0.0300, 0.0014, …, -0.0061, 0.0106, -0.0367] |
" :)" |
14373 | [ 0.0083, -0.0308, 0.0373, …, -0.0142, -0.0107, -0.0084] |
We can generate text from these token embeddings sending inputs_embeds instead of input_ids.
def llm_embed(prompt, max_length=30):
inputs = tokenizer(prompt, return_tensors="pt")
embeds = phi.model.embed_tokens(inputs.input_ids)
generated_ids = phi.generate(inputs_embeds=embeds,
attention_mask=inputs.attention_mask,
max_length=30)
return tokenizer.batch_decode(generated_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]Check everything is working by comparing the text generated with our original llm function2.
llm('Random number?') == llm_embed('Random number?')Now we have all the pieces we need to use nokens instead of tokens.
Generating With Random Nokens
Our first experiment is replacing a token with seeded randomness.
By using the token Red as the first word in our prompt, we ensure we replace this token with a noken. We replace the token embedding with random numbers of the same size/shape as the original token embedding.
def llm_rand(prompt, seed, loc=0):
inputs = tokenizer(prompt, return_tensors='pt')
# overwrite embedding of token at `loc` with seeded randomness
torch.manual_seed(seed)
embeds = phi.model.embed_tokens(inputs.input_ids)
embeds[0,loc,:] = torch.randn_like(embeds[0,loc,:])
# generate new tokens
generate_ids = phi.generate(inputs_embeds=embeds,
attention_mask=inputs.attention_mask,
max_length=30)
# return decoded tokens
return tokenizer.batch_decode(generate_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]
for seed in range(10):
print(llm_rand("Red is a color that is often associated with", seed))| Seed | Response |
|---|---|
| 0 | luxury and elegance. It is a deep, rich shade of brown that is often used in high-end |
| 1 | luxury and elegance. It is a deep, rich shade that is often used in high-end fashion and |
| 2 | the sun, fire, and energy. It is a bright and vibrant color that can evoke feelings of warmth |
| 3 | the color wheel. It is a combination of red and yellow, and it is a color that is often |
| 4 | the ocean and the sky. It is a deep, rich blue that can evoke feelings of calmness and |
| 5 | the ocean, the sky, and the sun. It is a bright and cheerful color that can evoke feelings |
| 6 | the ocean and the sky. It is a calming and soothing color that can help to create a sense of |
| 7 | the natural world. It is the color of the sky, the grass, and the leaves on trees. |
| 8 | luxury, elegance, and sophistication. It is a color that is often used in high-end fashion, |
| 9 | luxury and elegance. It is a color that is often used in high-end fashion and home decor. |
It worked! The LLM decided that different nokens have different color-ish meanings.
Generating With LERP’d Nokens
For our next experiment, we will LERP3 to blend two different tokens.
To simplify, let’s just LERP between two prompts that have the same number of tokens. The first word of both prompts is a single token (Black/White).
def llm_lerp(prompt_1: str, prompt_2: str, p: float) -> str:
inputs_1 = tokenizer(prompt_1, return_tensors='pt')
inputs_2 = tokenizer(prompt_2, return_tensors='pt')
embeds_1 = phi.model.embed_tokens(inputs_1.input_ids)
embeds_2 = phi.model.embed_tokens(inputs_2.input_ids)
if embeds_1.shape != embeds_2.shape:
raise ValueError('Embeddings must be the same shape')
embeds = (1-p) * embeds_1 + p * embeds_2
generate_ids = phi.generate(inputs_embeds=embeds,
attention_mask=inputs_1.attention_mask,
max_length=30)
return tokenizer.batch_decode(generate_ids,
skip_special_tokens=True,
clean_up_tokenization_spaces=False)[0]
for p in range(11):
p = p // 10
print(llm_lerp('White whippets are', 'Black whippets are', p))| Seed | Response |
|---|---|
| 0.0 | also known as the “dancing dog” because of their graceful movements. They are very active and love to run and play |
| 0.1 | also known as “snow dogs” because of their ability to pull sleds in snowy conditions. They have a thick, |
| 0.2 | also known as “snow dogs” because of their ability to pull sleds in snowy conditions. They have a thick, |
| 0.3 | also known as “snow whippets” because of their white coats. They are a popular breed for families with children |
| 0.4 | also known as “snow whippets” because of their white coats. They are a popular breed for families with children |
| 0.5 | also known as “snow whippets” because of their white coats. They are a popular breed for families with children |
| 0.6 | also known for their intelligence and trainability. They are eager to please their owners and can be easily trained to perform various tasks |
| 0.7 | also known for their intelligence and trainability. They are eager to please their owners and can be easily trained to perform various tasks |
| 0.8 | also known for their intelligence and trainability. They are eager to please their owners and can be easily trained to perform various tasks |
| 0.9 | also known for their intelligence and trainability. They are eager to please their owners and can be trained to do various tricks and |
| 1.0 | also known for their intelligence and trainability. They are eager to please their owners and can be trained to do various tricks and |
Success!
More Control - Generate one token at a time
Perhaps you want to mess with the embeddings of tokens that are not in the prompt. Perhaps trigger on specific tokens or interactively changing… I’ve got you covered, this code snippet is complex but exposes the inner workings of the model.
# helpers
logits_processor = LogitsProcessorList([
MinLengthLogitsProcessor(
15, eos_token_id=phi.generation_config.eos_token_id
),
])
logits_warper = LogitsProcessorList([
TopKLogitsWarper(1),
TemperatureLogitsWarper(0.01),
])
def embsampler(prompt="Red is the first", seed=0, tokens=10):
print("prompt:", prompt.replace("Red", "*"), " | ", end="")
past_key_values = None
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs.input_ids
attention_mask = inputs.attention_mask
inputs_embeds = phi.model.embed_tokens(input_ids)
# replace the first token with a random seeded noken
torch.manual_seed(seed)
inputs_embeds[:,0,:] = torch.randn_like(inputs_embeds[:,0,:])
for _ in range(tokens):
# run the core model
outputs = phi(
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
attention_mask=attention_mask,
use_cache=True,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
# outputs returns logits we need to process to determine the next token
next_token_logits = outputs.logits[:, -1, :]
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
probs = F.softmax(next_token_scores, dim=-1)
next_token = torch.multinomial(probs, num_samples=1).squeeze(1)
print(tokenizer.decode(next_token), end="")
# we use kvcache to speed things up, only seed new tokens
input_ids = next_token[:, None]
inputs_embeds = phi.model.embed_tokens(input_ids)
# this is the cache!
past_key_values = outputs.past_key_values
# attention_mask.append(1) .. but in torch :(
attention_mask = torch.cat(
[attention_mask, attention_mask.new_ones((attention_mask.shape[0], 1))],
dim=-1,
)
print()
for seed in range(0,11):
embsampler(seed=seed, tokens=20)| Seed | Response |
|---|---|
| 0 | to offer a comprehensive, integrated approach to the treatment of chronic pain. The program is designed to |
| 1 | of its kind in the world. The building is also home to the National Gallery of Victoria |
| 2 | to be built in the United States. Exercise: What is the purpose of the new |
| 3 | to be released in the series. Question: What is the plot of the game? |
| 4 | to offer a comprehensive, integrated solution for the management of the entire life cycle of a product, from |
| 5 | to admit that the idea of a “smart” city is still in its infancy. “We |
| 6 | step in the process of making a delicious and refreshing drink. The process of making a da |
| 7 | step in the process of creating a new drug. Exercise: What is the purpose of |
| 8 | to admit that the idea of a “perfect” marriage is a myth. “There is no such |
| 9 | album by the band The Black Crowes. It was released in 1988 and was produced by the band |
Success?
It “works” - but is it useful?
Unclear.
It seems interesting enough to continue. As transformers are used in more contexts and can do more, having a richer set of tools to interact with the model seems like a good idea.
I’m going to switch to Mistral or perhaps coding model. Or perhaps a musicgen model - fuzz the music!
Footnotes
In Mapping the semantic void: Strange goings-on in GPT embedding spaces, the author explores GPT-J’s token space and introduced me to the concept of non-tokens (nokens).↩︎
LLMs are determinstic by default. To add chaos you need to turn up the
temperatureor usetop_k/top_psampling.↩︎Linear intERPolation: a way to smoothly blend between two values.↩︎